Linux系统下wget命令的使用教程
一、Linux wget简介
wget是linux上的命令行的下载工具。这是一个GPL许可证下的自由软件。Linux wget支持HTTP和FTP协议,支持代理服务器和断点续传功能,能够自动递归远程主机的目录,找到合乎条件的文件并将其下载到本地硬盘上;如果必要,Linux wget将恰当地转换页面中的超级连接以在本地生成可浏览的镜像。由于没有交互式界面,Linux wget可在后台运行,截获并忽略HANGUP信号,因此在用户推出登录以后,仍可继续运行。通常,Linux wget用于成批量地下载Internet网站上的文件,或制作远程网站的镜像。
二、实例
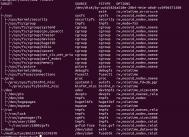
下载下载192.168.1.168首页并且显示下载信息Linux wget -d http://192.168.1.168下载192.168.1.168首页并且不显示任何信息wget -q http://192.168.1.168下载filelist.txt中所包含的链接的所有文件wget -i filelist.txt
下载到指定目录wget -P/tmp ftp://user:passwd@url/file把文件file下载到/tmp目录下。Linux wget是一个命令行的下载工具。对于我们这些 Linux 用户来说,几乎每天都在使用它。下面为大家介绍几个有用的 Linux wget 小技巧,可以让你更加高效而灵活的使用 Linux wget。
*
代码如下:
$ wget -r -np -nd http://example.com/packages/
这条命令可以下载 http://example.com 网站上 packages 目录中的所有文件。其中,-np 的作用是不遍历父目录,-nd 表示不在本机重新创建目录结构。
*
代码如下:
$ wget -r -np -nd --accept=iso http://example.com/centos-5/i386/
与上一条命令相似,但多加了一个 --accept=iso 选项,这指示Linux wget仅下载 i386 目录中所有扩展名为 iso 的文件。你也可以指定多个扩展名,只需用逗号分隔即可。
*
复制代码
代码如下:
$ wget -i filename.txt
此命令常用于批量下载的情形,把所有需要下载文件的地址放到 filename.txt 中,然后 Linux wget就会自动为你下载所有文件了。
*
复制代码
代码如下:
$ wget -c http://example.com/really-big-file.iso
这里所指定的 -c 选项的作用为断点续传。
*
复制代码
代码如下:
$ wget -m -k (-H) http://www.example.com/
该命令可用来镜像一个网站,Linux wget将对链接进行转换。如果网站中的图像是放在另外的站点,那么可以使用 -H 选项。
三、参数
代码:
复制代码
代码如下:
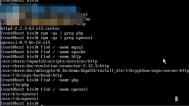
$ wget --helpGNU Wget 1.9.1
,非交互式的网络文件下载工具。用法:Linux wget[选项]... [URL]...长选项必须用的参数在使用短选项时也是必须的。
启动:
-V, --version 显示 Wget 的版本并且退出。
-h, --help 打印此帮助。
-b, -background 启动后进入后台操作。
-e, -execute=COMMAND 运行‘.wgetrc’形式的命令。
日志记录及输入文件:
-o, --output-file=文件 将日志消息写入到指定文件中。
-a, --append-output=文件 将日志消息追加到指定文件的末端。
-d, --debug 打印调试输出。
-q, --quiet 安静模式(不输出信息)。
-v, --verbose 详细输出模式(默认)。
-nv, --non-verbose 关闭详细输出模式,但不进入安静模式。
-i, --input-file=文件 下载从指定文件中找到的 URL。
-F, --force-html 以 HTML 方式处理输入文件。
-B, --base=URL 使用 -F -i 文件选项时,在相对链接前添加指定的 URL。
下载:
-t, --tries=次数 配置重试次数(0 表示无限)。
--retry-connrefused 即使拒绝连接也重试。
-O --output-document=文件 将数据写入此文件中。
-nc, --no-clobber 不更改已经存在的文件,也不使用在文件名后添加 .#(# 为数字)的方法写入新的文件。
-c, --continue 继续接收已下载了一部分的文件。
--progress=方式 选择下载进度的表示方式。
-N, --timestamping 除非远程文件较新,否则不再取回。
-S, --server-response 显示服务器回应消息。
--spider 不下载任何数据。
-T, --timeout=秒数 配置读取数据的超时时间 (秒数)。
-w, --wait=秒数 接收不同文件之间等待的秒数。
--waitretry=秒数 在每次重试之间稍等一段时间 (由 1 秒至指定的 秒数不等)。
--random-wait 接收不同文件之间稍等一段时间(由 0 秒至 2*WAIT 秒不等)。
-Y, --proxy=on/off 打开或关闭代理服务器。
-Q, --quota=大小 配置接收数据的限额大小。
--bind-address=地址 使用本机的指定地址 (主机名称或 IP) 进行连接。
--limit-rate=速率 限制下载的速率。
--dns-cache=off 禁止查找存于高速缓存中的 DNS。
--restrict-file-names=OS 限制文件名中的字符为指定的 OS (操作系统) 所允许的字符。
目录:
-nd --no-directories 不创建目录。
-x, --force-directories 强制创建目录。
-nH, --no-host-directories 不创建含有远程主机名称的目录。
-P, --directory-prefix=名称 保存文件前先创建指定名称的目录。
--cut-dirs=数目 忽略远程目录中指定数目的目录层。
HTTP 选项:
--http-user=用户 配置 http 用户名。
(本文来源于图老师网站,更多请访问https://m.tulaoshi.com/fuwuqi/)--http-passwd=密码 配置 http 用户密码。
-C, --cache=on/off (不)使用服务器中的高速缓存中的数据 (默认是使用的)。
-E, --html-extension 将所有 MIME 类型为 text/html 的文件都加上 .html 扩展文件名。
--ignore-length 忽略Content-Length文件头字段。
--header=字符串 在文件头中添加指定字符串。
--proxy-user=用户 配置代理服务器用户名。
--proxy-passwd=密码 配置代理服务器用户密码。
--referer=URL 在 HTTP 请求中包含Referer:URL头。
-s, --save-headers 将 HTTP 头存入文件。
-U, --user-agent=AGENT 标志为 AGENT 而不是 Wget/VERSION。
--no-http-keep-alive 禁用 HTTP keep-alive(持久性连接)。
--cookies=off 禁用 cookie。
--load-cookies=文件 会话开始前由指定文件载入 cookie。
--save-cookies=文件 会话结束后将 cookie 保存至指定文件。
--post-data=字符串 使用 POST 方法,发送指定字符串。
--post-file=文件 使用 POST 方法,发送指定文件中的内容。
HTTPS (SSL) 选项:
--sslcertfile=文件 可选的客户段端证书。
--sslcertkey=密钥文件 对此证书可选的密钥文件。
--egd-file=文件 EGD socket 文件名。
--sslcadir=目录 CA 散列表所在的目录。
--sslcafile=文件 包含 CA 的文件。
--sslcerttype=0/1 Client-Cert 类型 0=PEM (默认) / 1=ASN1 (DER)
--sslcheckcert=0/1 根据提供的 CA 检查服务器的证书
--sslprotocol=0-3 选择 SSL 协议;0=自动选择,
1=SSLv2 2=SSLv3 3=TLSv1
FTP 选项:
-nr, --dont-remove-listing 不删除.listing文件。
-g, --glob=on/off 设置是否展开有通配符的文件名。
--passive-ftp 使用被动传输模式。
--retr-symlinks 在递归模式中,下载链接所指示的文件(连至目录则例外)。
递归下载:
-r, --recursive 递归下载。
-l, --level=数字 最大递归深度(inf 或 0 表示无限)。
--delete-after 删除下载后的文件。
-k, --convert-links 将绝对链接转换为相对链接。
-K, --backup-converted 转换文件 X 前先将其备份为 X.orig。
-m, --mirror 等效于 -r -N -l inf -nr 的选项。
-p, --page-requisites 下载所有显示完整网页所需的文件,例如图像。
--strict-comments 打开对 HTML 备注的严格(SGML)处理选项。
递归下载时有关接受/拒绝的选项:
-A, --accept=列表 接受的文件样式列表,以逗号分隔。
-R, --reject=列表 排除的文件样式列表,以逗号分隔。
-D, --domains=列表 接受的域列表,以逗号分隔。
--exclude-domains=列表 排除的域列表,以逗号分隔。
--follow-ftp 跟随 HTML 文件中的 FTP 链接。
--follow-tags=列表 要跟随的 HTML 标记,以逗号分隔。
-G, --ignore-tags=列表 要忽略的 HTML 标记,以逗号分隔。
-H, --span-hosts 递归时可进入其它主机。
-L, --relative 只跟随相对链接。
-I, --include-directories=列表 要下载的目录列表。
-X, --exclude-directories=列表 要排除的目录列表。
-np, --no-parent 不搜索上层目录。
四、实例:用Wget批量下载远程FTP服务器上的文件
昨天买了个VPS,把虚拟主机迁移到VPS了,迁移过程肯定是要转移数据的。以前虚拟主机迁移数据的模式是非常低效率的,旧主机打包下载-新主机上传再解压缩,由于家庭网络带宽非常低,而且ADSL的上行速率512kbps万年不变,导致以前迁移网站绝对是体力活...
现在有了VPS,有了shell,这个过程就无比简单了,借助机房的大带宽,直接机房对机房互传文件看着简直就是一种享受啊

好了,讲一下方法:
1、旧虚拟主机打包备份整站 site.tar.gz
2、在VPS的shell中利用wget下载旧虚拟主机中的site.tar.gz,使用FTP协议
代码如下:
wget --ftp-user=username --ftp-password=password -m -nh ftp://xxx.xxx.xxx.xxx/xxx/xxx/site.tar.gz
pwget --ftp-user=username --ftp-password=password -r -m -nh ftp://xxx.xxx.xxx.xxx/xxx/xxx/*
上面就是命令了,FTP用户名密码参数不解释;
-r 可选,表示递归下载,如果直接下载整个目录就需要该参数;
-m 表示镜像,不解释;
-nh表示不生成那一堆层级目录,直接从当前目录开始显示,非常好的参数;
后面是ftp的地址,斜杠后的 * 表示下载该目录下的所有文件,如果只是一个文件,直接输入文件名即可。
五、Q&A
A.使用wget工具linux所以的主要版本都自带了Linux wget这个下载工具.bash$ wget http://place.your.url/here它还能控制ftp来下载整个web站点的各级目录,当然,如果你不小心,可能会把整个网站以及其他和他做链接的网站全部下载下来.bash$ wget -m http://target.web.site/subdirectory由于这个工具具有很强的下载能力,所以可以在服务器上把它用作镜像网站的工具.让它按照robots.txt的规定来执行.有很多参数用来控制它如何正确地做镜像,可以限制链接的类型和下载文件的类型等等.例如:只下载有联系的链接并且忽略GIF图片:
代码如下:
bash$ wget -m -L –reject=gif http://target.web.site/subdirectory
Linux wget也能够实现断点续传(-c参数),当然,这种操作是需要远程服务器支持的.
代码如下:
bash$ wget -c http://the.url.of/incomplete/file
可以把断点续传和镜像功能结合起来,这样可以在以前断过多次的情况下继续镜像一个有大量选择性文件的站点.如何自动实现这个目的我们在后面会讨论得更多.
如果你觉得下载时老是断线会影响你办公的话,你可以限制Linux wget重试的次数.
代码如下:
bash$ wget -t 5 http://place.your.url/here
这样重试五次后就放弃了.用-t inf参数表示永远不放弃.不停地重试.
B.那对于代理服务该怎么办呢?可以使用http代理的参数或者在.wgetrc配置文件里指定一个如何通过代理去下载的途径.但是有这么一个问题,如果通过代理来进行断点续传的话可能会有几次失败.如果有一次通过代理下载的过程发生中断,那么代理服务器上缓存里保存是那个完整的文件拷贝. 所以当你用wget -c来下载剩余部分的时候代理服务器查看它的缓存,并错误地认为你已经下载了整个文件.于是就发出了错误的信号.这个时候你可以用添加一个特定的请求参数来促使代理服务器清除他们的缓存:
代码如下:
bash$ wget -c –header=Pragma: no-cache http://place.your.url/here
这个–header参数能够以各种数字,各种方式添加。通过它我们可以更改web服务器或者代理服务器的某些属性。有些站点不提供外部连接的文件服务,只有通过同一个站点上其他的一些页面时内容才会被提交。这个时候你可以用加上Referer:参数:bash$ wget –header=Referer: http://coming.from.this/page http://surfing.to.this/page有些特殊的网站只支持某种特定的浏览器,这个时候可以用User-Agent:参数bash$ wget –header=User-Agent: Mozilla/4.0 (compatible; MSIE 5.0;Windows NT; DigExt) http://msie.only.url/here
C.那我怎么设定下载时间呢?
如果你需要在你的办公电脑上通过和其他同事共享的一个连接来下载一些很大的文件,而且你希望你的同事不会因为网络速度的减慢而收到影响,那你就应该尽量避开高峰时段。当然,不需要在办公室里等到所以人都走掉,也不需要在家里用完晚饭后还惦记着要上网下载一次。用at来就可以很好的定制工作时间:bash$ at 23:00warning: commands will be executed using /bin/shat wget http://place.your.url/hereat press Ctrl-D这样,我们设定了下载工作在晚上11点进行。为了使这个安排能够正常进行,请确认atd这个后台程序正在运行。
D.下载要花很多时间?
当你需要下载大量的数据,而且你又没有享有足够的带宽,这个时候你会经常发现在你安排的下载任务还没有完成,一天的工作却又要开始了。
作为一个好同事,你只能停掉了这些任务,而开始另外的工作。然后你又需要反复地重复使用wget -c来完成你的下载。这样肯定太繁琐了,所以最好是用crontab来自动执行。创建一个纯文本文件,叫做crontab.txt,包含下面的内容:0 23 * * 1-5 wget -c -N http://place.your.url/here0 6 * * 1-5 killall wgetz这个crontab文件指定某些任务定期地执行。前五列声明是什么时候执行这个命令,而每行的剩余部分则告诉crontab执行什么内容。
前两列指定了每天一到晚上11点就开始用Linux wget下载,一到早上6点就停止一切Linux wget下载。第三四列的*表示每个月的每一天都执行这个任务。第五列则指定了一个星期的哪几天来执行这个程序。 –1-5″表示从星期一到星期五。这样在每个工作日的晚上11点,下载工作开始,到了上午的6点,任何的Linux wget任务就被停掉了。你可以用下面的命令来执行
(本文来源于图老师网站,更多请访问https://m.tulaoshi.com/fuwuqi/)代码如下:
crontab:bash$ crontab crontab.txt
Linux wget的这个-N参数将会检查目标文件的时间戳,如果匹配了,下载程序就会停止,因为它说明整个文件已经下载完全了。用crontab -r可以删除这个计划安排。我已经多次采用这种方法,通过共享的电话拨号来下载过很多的ISO镜像文件,还是比较实用的。
E.如何下载动态变化的网页
有些网页每天都要根据要求变化好几次.所以从技术上讲,目标不再是一个文件,它没有文件长度.因此-c这个参数也就失去了意义.例如:一个PHP写的并且经常变动的linux周末新闻网页:
代码如下:
bash$ wget http://lwn.net/bigpage.php3
我办公室里的网络条件经常很差,给我的下载带了很大的麻烦,所以我写了个简单的脚本来检测动态页面是否已经完全更新了.
代码如下:
#!/bin/bash
#create it if absent
touch bigpage.php3
#check if we got the whole thing
while ! grep -qi bigpage.php3
do
rm -f bigpage.php3
#download LWN in one big page
wget http://lwn.net/bigpage.php3
done
这个脚本能够保证持续的下载该网页,直到网页里面出现了" ",这就表示该文件已经完全更新了.
F.对于ssl和Cookies怎么办?
如果你要通过ssl来上网,那么网站地址应该是以https://来开头的.在这样的情况下你就需要另外一种下载工具,叫做curl,它能够很容易获得.有些网站迫使网友在浏览的时候必须使用cookie.所以你必须从在网站上得到的那个 Cookie里面得到Cookie:这个参数.这样才能保证下载的参数正确.对于lynx和Mozilla的Cookie的文件格式,用下面的:
代码如下:
bash$ cookie=$( grep nytimes ~/.lynx_cookies |awk {printf(%s=%s;,$6,$7)} )
就可以构造一个请求Cookie来下载http://www.nytimes.com上的内容.当然,你要已经用这个浏览器在该网站上完成注册.w3m使用了一种不同的,更小巧的Cookie文件格式:
代码如下:
bash$ cookie=$( grep nytimes ~/.w3m/cookie |awk {printf(%s=%s;,$2,$3)} )
现在就可以用这种方法来下载了:
代码如下:
bash$ wget –header=Cookie: $cookie http://www.nytimes.com/reuters/technology/tech-tech-supercomput.html
或者用curl工具:
代码如下:
bash$ curl -v -b $cookie -o supercomp.html http://www.nytimes.com/reuters/technology/tech-tech-supercomput.htm
G.如何建立地址列表?
到现在为止我们下载的都是单个文件或者是整个网站.有的时候我们需要下载某个网页上链接的大量文件,但没有必要把它整个网站都镜像下来.比如说我们想从一个依次排列的100首歌里面下载前20首.注意,这里–accept和–reject参数是不会起作用的, 因为他们只对文件操作起作用.所以一定要用lynx -dump参数来代替.
代码如下:
bash$ lynx -dump ftp://ftp.ssc.com/pub/lg/ |grep gz$ |tail -10 |awk {print $2} urllist.txt
lynx的输出结果可以被各种GNU文本处理工具过虑.在上面的例子里,我们的链接地址是以gz结尾的,并且把最后10个文件地址放到urllist.txt文件里.然后我们可以写一个简单的bash脚本来自动下载这个文件里的目标文件:
代码如下:
bash$ for x in $(cat urllist.txt)
do
wget $x
done
这样我们就能够成功下载Linux Gazette网站(ftp://ftp.ssc.com/pub/lg/)上的最新10个论题.
H.扩大使用的带宽
如果你选择下载一个受带宽限制的文件,那你的下载会因为服务器端的限制而变得很慢.下面这个技巧会大大缩短下载的过程.但这个技巧需要你使用curl并且远程服务器有多个镜像可以供你下载.例如,假设你想从下面的三个地址下载Mandrake 8.0:
代码如下:
url1=http://ftp.eecs.umich.edu/pub/linux/mandrake/iso/Mandrake80-inst.iso
url2=http://ftp.rpmfind.net/linux/Mandrake/iso/Mandrake80-inst.iso
url3=http://ftp.wayne.edu/linux/mandrake/iso/Mandrake80-inst.iso
这个文件的长度是677281792个字节,所以用curl程序加–range参数来建立三个同时进行的下载:
代码如下:
bash$ curl -r 0-199999999 -o mdk-iso.part1 $url1 &
bash$ curl -r 200000000-399999999 -o mdk-iso.part2 $url2 &
bash$ curl -r 400000000- -o mdk-iso.part3 $url3 &
这样就创建了三个后台进程.每个进程从不同的服务器传输这个ISO文件的不同部分.这个-r参数指定目标文件的字节范围.当这三个
进程结束后,用一个简单的cat命令来把这三个文件衔接起来– cat mdk-iso.part? mdk-80.iso.(强烈建议在刻盘之前先检查md5)
你也可以用–verbose参数来使每个curl进程都有自己的窗口来显示传输的过程.