数据库备份和还原的几种方法
方法一:通过企业管理器进行单个数据库备份
打开SQL SERVER 企业管理器,展开SQL SERVER组LOCAL下的数据库,右键点击你要备份的数据库,在弹出的菜单中选择所有任务下的备份数据库,弹出备份数据库对话框:
点击添加按钮,填写备份文件的路径和文件名,点击确定添加备份文件,点击备份对话框上的备份,开始进行备份。

方法二:通过企业管理器多数据定时库备份
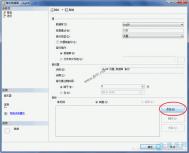
打开SQL SERVER 企业管理器,展开SQL SERVER组下的管理节点,右键单击数据库维护计划,选择新建维护计划。在弹出的欢迎对话框中选择下一步,然后显示如下对话框:

选择你想要备份的数据库,下一步。在接下来的一步中,我们默认所有选项,下一步。在当前对话框中可以选择是否检查数据库的完整性,这里我们默认就可以进行下一步就行了。对话框入图所示:

选中作为维护计划的一部分来备份数据库,点击更改按钮修改备份数据库的时间,单击下一步,入下图:
在这里,我们可以选择“使用此目录”为备份指定路径,选中“删除早于此时间的文件”可以指定备份文件的保留时间。

下面的几个步骤我们都选择默认设置,最后在完成对话框里为备份起一个名字,点击完成后,数据库会在你指定的时间进行备份。关于数据库维护计划的更多知识请查看其它相关资料。
方法三:备份数据库文件
打开SQL SERVER 企业管理器,展开SQL SERVER组LOCAL下的数据库,右键点击你要备份的数据库,选择属性。在弹出的对话框中选择数据文件,在这里显示了数据文件的路径,如下图:
打开SQL SERVER 服务管理器,将SQL SERVER 停止。然后打开我的电脑,找到数据文件路径,将其拷贝出来进行备份(注意同时备份.LDF文件)。
最后开启SQL SERVER服务

方法四:回复数据库备份文件(适用于用企业管理器备份的数据库)
打开SQL SERVER 企业管理器,展开SQL SERVER组LOCAL下的数据库,右键点击你要还原的数据库,选择所有任务下的还原数据库,弹出如下对话框:
选择从设备,点击选择设备,为还原添加备份文件路径,然后进行确定还原。

方法五:还原数据库备份文件
在企业管理器中对数据库节点右键单击,选择所有任务下的附加数据库,弹出附加数据库对话框。
选择一个你之前拷贝的数据文件,然后点击确定即可附加成功(注:如果数据库已经存在,请删除)
MSSQL数据库使用方法
1、 打开本地计算机上的 SQL Server Management Studio 客户端软件:

2、登陆本机数据库控制端:

3、选择生成SQL脚本:

4、选中需要导出脚本的库名:

5、选择兼容sql2005的版本的脚本:

6、修改sql脚本的保存路径:

7、查看生产脚本生成的选项:

8、成功生成sql脚本:

9、等待脚本生成完毕,进入存放目录用记事本打开脚本文件,修改库名为中电云集提供的数据库名,并确保您的脚本中所有者是 DBO,否则请替换成 DBO:

10、连接到中电云集提供的目标数据库服务器:
注:IP一项也可以填入数据库服务器的域名:us*-**.hichina.com(us******)

11、并点击新建查询,拷贝您记事本中的 SQL 脚本代码到上图显示的查询分析器中,点击分析脚本,如果没有语法错误,就点击执行脚本,直到执行完毕。

到此,您的数据库架构已经完整的导入到中电云集的数据库服务器。
二、下面咱们开始导入数据库表中的数据:
1、登陆您本地的数据库:

2、点击您本地计算机上的数据库右键-任务-导出数据:


3、选择目标数据库,如下添加中电云集提供给您的数据库信息(服务器地址,用户名,密码,数据库):

4、点击下一步:

5、点击下一步,选中所有表,并确保“目标”中是 DBO 的所有者:

6、点击下一步:

7、点击下一步,直到执行完毕:

8、成功导入数据:

到此,您的库已经完整的导入中电云集提供的数据库服务器中,您可以用程序进行调用读取了。
mssql数据库单表导入导出方法
首先要启动xp_cmdshell,最后还要关闭xp_cmdshell,中间执行导入导出语句。
默认情况下,sql server2005安装完后,xp_cmdshell是禁用的(可能是安全考虑),如果要使用它,可按以下步骤
-- 允许配置高级选项
EXEC sp_configure 'show advanced options', 1
GO
(本文来源于图老师网站,更多请访问http://m.tulaoshi.com/sqlserver/)-- 重新配置
RECONFIGURE
GO
(本文来源于图老师网站,更多请访问http://m.tulaoshi.com/sqlserver/)-- 启用xp_cmdshell
(本文来源于图老师网站,更多请访问http://m.tulaoshi.com/sqlserver/)EXEC sp_configure 'xp_cmdshell', 1
GO
(本文来源于图老师网站,更多请访问http://m.tulaoshi.com/sqlserver/)--重新配置
RECONFIGURE
GO
(本文来源于图老师网站,更多请访问http://m.tulaoshi.com/sqlserver/)----------------------------------------------------------------
--执行想要的xp_cmdshell语句
Exec xp_cmdshell 'query user'
GO
(本文来源于图老师网站,更多请访问http://m.tulaoshi.com/sqlserver/)----------------------------------------------------------------
--修改为
--------数据库名----------------------数据库名-----表名---------导入导出标志-----导入导出位置---------服务名称------用户名---密码
EXEC busDB..xp_cmdshell 'bcp busDB..FhCollectInfoTBbak in J:FhCollectInfoTB.txt -c -Servername -Uname -Ppassword'
EXEC busDB..xp_cmdshell 'bcp busDB..FhCollectInfoTBbak out J:FhCollectInfoTB.txt -c -Servername -Uname -Ppassword'
-----------
----------------------------------------------------------------
--用完后,要记得将xp_cmdshell禁用(出于安全考虑)
-- 允许配置高级选项
EXEC sp_configure 'show advanced options', 1
GO
(本文来源于图老师网站,更多请访问http://m.tulaoshi.com/sqlserver/)-- 重新配置
RECONFIGURE
GO
(本文来源于图老师网站,更多请访问http://m.tulaoshi.com/sqlserver/)-- 禁用xp_cmdshell
EXEC sp_configure 'xp_cmdshell', 0
GO
(本文来源于图老师网站,更多请访问http://m.tulaoshi.com/sqlserver/)--重新配置
RECONFIGURE
GO
(本文来源于图老师网站,更多请访问http://m.tulaoshi.com/sqlserver/)
数据库常见的17个典型问题
1. 给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
方案1:可以估计每个文件安的大小为50G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。
s 遍历文件a,对每个url求取,然后根据所取得的值将url分别存储到1000个小文件(记为)中。这样每个小文件的大约为300M。
s 遍历文件b,采取和a相同的方式将url分别存储到1000各小文件(记为)。这样处理后,所有可能相同的url都在对应的小文件()中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
s 求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
方案2:如果允许有一定的错误率,可以使用Bloom filter,4G内存大概可以表示340亿bit。将其中一个文件中的url使用Bloom filter映射为这340亿bit,然后挨个读取另外一个文件的url,检查是否与Bloom filter,如果是,那么该url应该是共同的url(注意会有一定的错误率)。
2. 有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序。
方案1:
s 顺序读取10个文件,按照hash(query)%10的结果将query写入到另外10个文件(记为)中。这样新生成的文件每个的大小大约也1G(假设hash函数是随机的)。
s 找一台内存在2G左右的机器,依次对用hash_map(query, query_count)来统计每个query出现的次数。利用快速/堆/归并排序按照出现次数进行排序。将排序好的query和对应的query_cout输出到文件中。这样得到了10个排好序的文件(记为)。
s 对这10个文件进行归并排序(内排序与外排序相结合)。
方案2:
一般query的总量是有限的,只是重复的次数比较多而已,可能对于所有的query,一次性就可以加入到内存了。这样,我们就可以采用trie树/hash_map等直接来统计每个query出现的次数,然后按出现次数做快速/堆/归并排序就可以了。
方案3:
与方案1类似,但在做完hash,分成多个文件后,可以交给多个文件来处理,采用分布式的架构来处理(比如MapReduce),最后再进行合并。
3. 有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
方案1:顺序读文件中,对于每个词x,取,然后按照该值存到5000个小文件(记为)中。这样每个文件大概是200k左右。如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,知道分解得到的小文件的大小都不超过1M。对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树/hash_map等),并取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100词及相应的频率存入文件,这样又得到了5000个文件。下一步就是把这5000个文件进行归并(类似与归并排序)的过程了。

4. 海量日志数据,提取出某日访问百度次数最多的那个IP。
方案1:首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有个IP。同样可以采用映射的方法,比如模1000,把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000个最大的IP中,找出那个频率最大的IP,即为所求。
5. 在2.5亿个整数中找出不重复的整数,内存不足以容纳这2.5亿个整数。
方案1:采用2-Bitmap(每个数分配2bit,00表示不存在,01表示出现一次,10表示多次,11无意义)进行,共需内存内存,还可以接受。然后扫描这2.5亿个整数,查看Bitmap中相对应位,如果是00变01,01变10,10保持不变。所描完事后,查看bitmap,把对应位是01的整数输出即可。
方案2:也可采用上题类似的方法,进行划分小文件的方法。然后在小文件中找出不重复的整数,并排序。然后再进行归并,注意去除重复的元素。
6. 海量数据分布在100台电脑中,想个办法高校统计出这批数据的TOP10。
方案1:
s 在每台电脑上求出TOP10,可以采用包含10个元素的堆完成(TOP10小,用最大堆,TOP10大,用最小堆)。比如求TOP10大,我们首先取前10个元素调整成最小堆,如果发现,然后扫描后面的数据,并与堆顶元素比较,如果比堆顶元素大,那么用该元素替换堆顶,然后再调整为最小堆。最后堆中的元素就是TOP10大。
s 求出每台电脑上的TOP10后,然后把这100台电脑上的TOP10组合起来,共1000个数据,再利用上面类似的方法求出TOP10就可以了。
7. 怎么在海量数据中找出重复次数最多的一个?
方案1:先做hash,然后求模映射为小文件,求出每个小文件中重复次数最多的一个,并记录重复次数。然后找出上一步求出的数据中重复次数最多的一个就是所求(具体参考前面的题)。
8. 上千万或上亿数据(有重复),统计其中出现次数最多的钱N个数据。
方案1:上千万或上亿的数据,现在的机器的内存应该能存下。所以考虑采用hash_map/搜索二叉树/红黑树等来进行统计次数。然后就是取出前N个出现次数最多的数据了,可以用第6题提到的堆机制完成。

9. 1000万字符串,其中有些是重复的,需要把重复的全部去掉,保留没有重复的字符串。请怎么设计和实现?
方案1:这题用trie树比较合适,hash_map也应该能行。
10. 一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析。
方案1:这题是考虑时间效率。用trie树统计每个词出现的次数,时间复杂度是O(n*le)(le表示单词的平准长度)。然后是找出出现最频繁的前10个词,可以用堆来实现,前面的题中已经讲到了,时间复杂度是O(n*lg10)。所以总的时间复杂度,是O(n*le)与O(n*lg10)中较大的哪一个。
11. 一个文本文件,找出前10个经常出现的词,但这次文件比较长,说是上亿行或十亿行,总之无法一次读入内存,问最优解。
方案1:首先根据用hash并求模,将文件分解为多个小文件,对于单个文件利用上题的方法求出每个文件件中10个最常出现的词。然后再进行归并处理,找出最终的10个最常出现的词。
12. 100w个数中找出最大的100个数。
方案1:在前面的题中,我们已经提到了,用一个含100个元素的最小堆完成。复杂度为O(100w*lg100)。
方案2:采用快速排序的思想,每次分割之后只考虑比轴大的一部分,知道比轴大的一部分在比100多的时候,采用传统排序算法排序,取前100个。复杂度为O(100w*100)。
方案3:采用局部淘汰法。选取前100个元素,并排序,记为序列L。然后一次扫描剩余的元素x,与排好序的100个元素中最小的元素比,如果比这个最小的要大,那么把这个最小的元素删除,并把x利用插入排序的思想,插入到序列L中。依次循环,知道扫描了所有的元素。复杂度为O(100w*100)。
13. 寻找热门查询:
搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。假设目前有一千万个记录,这些查询串的重复读比较高,虽然总数是1千万,但是如果去除重复和,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就越热门。请你统计最热门的10个查询串,要求使用的内存不能超过1G。
(1) 请描述你解决这个问题的思路;
(2) 请给出主要的处理流程,算法,以及算法的复杂度。
方案1:采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的最小推来对出现频率进行排序。

14. 一共有N个机器,每个机器上有N个数。每个机器最多存O(N)个数并对它们操作。如何找到个数中的中数?
方案1:先大体估计一下这些数的范围,比如这里假设这些数都是32位无符号整数(共有个)。我们把0到的整数划分为N个范围段,每个段包含个整数。比如,第一个段位0到,第二段为到,…,第N个段为到。然后,扫描每个机器上的N个数,把属于第一个区段的数放到第一个机器上,属于第二个区段的数放到第二个机器上,…,属于第N个区段的数放到第N个机器上。注意这个过程每个机器上存储的数应该是O(N)的。下面我们依次统计每个机器上数的个数,一次累加,直到找到第k个机器,在该机器上累加的数大于或等于,而在第k-1个机器上的累加数小于,并把这个数记为x。那么我们要找的中位数在第k个机器中,排在第位。然后我们对第k个机器的数排序,并找出第个数,即为所求的中位数。复杂度是的。
方案2:先对每台机器上的数进行排序。排好序后,我们采用归并排序的思想,将这N个机器上的数归并起来得到最终的排序。找到第个便是所求。复杂度是的。
15. 最大间隙问题
给定n个实数,求着n个实数在实轴上向量2个数之间的最大差值,要求线性的时间算法。
方案1:最先想到的方法就是先对这n个数据进行排序,然后一遍扫描即可确定相邻的最大间隙。但该方法不能满足线性时间的要求。故采取如下方法:
s 找到n个数据中最大和最小数据max和min。
s 用n-2个点等分区间[min, max],即将[min, max]等分为n-1个区间(前闭后开区间),将这些区间看作桶,编号为,且桶的上界和桶i+1的下届相同,即每个桶的大小相同。每个桶的大小为:。实际上,这些桶的边界构成了一个等差数列(首项为min,公差为),且认为将min放入第一个桶,将max放入第n-1个桶。
s 将n个数放入n-1个桶中:将每个元素分配到某个桶(编号为index),其中,并求出分到每个桶的最大最小数据。
s 最大间隙:除最大最小数据max和min以外的n-2个数据放入n-1个桶中,由抽屉原理可知至少有一个桶是空的,又因为每个桶的大小相同,所以最大间隙不会在同一桶中出现,一定是某个桶的上界和气候某个桶的下界之间隙,且该量筒之间的桶(即便好在该连个便好之间的桶)一定是空桶。也就是说,最大间隙在桶i的上界和桶j的下界之间产生。一遍扫描即可完成。
16. 将多个集合合并成没有交集的集合:给定一个字符串的集合,格式如:。要求将其中交集不为空的集合合并,要求合并完成的集合之间无交集,例如上例应输出。
(1) 请描述你解决这个问题的思路;
(2) 给出主要的处理流程,算法,以及算法的复杂度;
(3) 请描述可能的改进。

方案1:采用并查集。首先所有的字符串都在单独的并查集中。然后依扫描每个集合,顺序合并将两个相邻元素合并。例如,对于,首先查看aaa和bbb是否在同一个并查集中,如果不在,那么把它们所在的并查集合并,然后再看bbb和ccc是否在同一个并查集中,如果不在,那么也把它们所在的并查集合并。接下来再扫描其他的集合,当所有的集合都扫描完了,并查集代表的集合便是所求。复杂度应该是O(NlgN)的。改进的话,首先可以记录每个节点的根结点,改进查询。合并的时候,可以把大的和小的进行合,这样也减少复杂度。
17. 最大子序列与最大子矩阵问题
数组的最大子序列问题:给定一个数组,其中元素有正,也有负,找出其中一个连续子序列,使和最大。
方案1:这个问题可以动态规划的思想解决。设表示以第i个元素结尾的最大子序列,那么显然。基于这一点可以很快用代码实现。
最大子矩阵问题:给定一个矩阵(二维数组),其中数据有大有小,请找一个子矩阵,使得子矩阵的和最大,并输出这个和。
方案1:可以采用与最大子序列类似的思想来解决。如果我们确定了选择第i列和第j列之间的元素,那么在这个范围内,其实就是一个最大子序列问题。如何确定第i列和第j列可以词用暴搜的方法进行。

数据库分页大全
Mysql分页采用limt关键字
select
*
from
t_order
limit
5,10;
#返回第6-15行数据
select
*
from
t_order limit
5; #返回前5行
select
*
from
t_order limit
0,5;
#返回前5行
Mssql 2000分页采用top关键字(20005以上版本也支持关键字rownum)
Select top 10 * from t_order where id not in (select id from t_order where id>5 ); //返回第6到15行数据
其中10表示取10记录 5表示从第5条记录开始取

Oracle分页
①采用rownum关键字(三层嵌套)
SELECT * FROM(
SELECT A.*,ROWNUM
num FROM
(SELECT * FROM t_order)A
WHERE
ROWNUM<=15)
WHERE num>=5;--返回第5-15行数据
②采用row_number解析函数进行分页(效率更高)
SELECT xx.* FROM(
SELECT t.*,row_number() over(ORDER BY o_id)AS num
FROM t_order t
)xx
WHERE num BETWEEN 5 AND 15;
--返回第5-15行数据
解析函数能用格式
函数() over(pertion by 字段 order by 字段);
Pertion 按照某个字段分区
Order 按照勒个字段排序

总结:mssql数据库是现下网站服务器常用的数据调用工具,除了设定需要的规则以外,更需要注重安全问题。以上关于mssql数据的问题是否有帮助到你呢?想要了解更多mssql数据问题就进入图老师搜索吧!
| 数据库编程知识大全 |
| 网络编程 |
| 视频编辑软件 |
| 网页编辑器 |
| 编程语言 |
| 汇编语言 |
| Linux编程 |
| 编程器技巧 |
| mysql数据库 |